
Here, we show the strength of our custom machine learning (ML) solutions. We have created a platform that lets us do efficient machine learning on very large datasets with little effort from the user.
For example, one of our clients had TBs of data stored on their own on-premises servers and wanted to start using predictive analytics to improve their forecasting of different business areas.
We first set up an easy process for them to move their data to the cloud (specifically Google Cloud Platform’s BigQuery). This allowed: 1) their business intelligence (BI) team to access the data and create reports, and 2) their data science team to collaborate with us to build several models using these large datasets.
We showcase some of this work below. Since the data we worked with is proprietary, our demo below uses a large publicly available dataset.
In this case, similar to one of the datasets we were working with with this client is the NYC Taxi Trips Dataset:
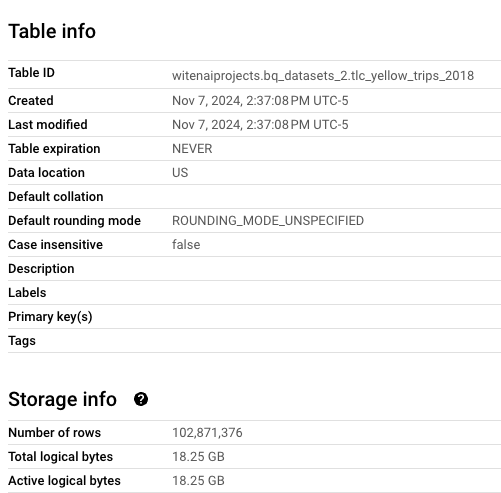
As you can see from the GCP BigQuery screenshot above, the dataset we are using is roughly 18.25 GB in size and has in excess of 100M rows. (An important point is that we are able to deal with datasets that are much larger, what we showcase is just for demo purposes. Further, we are able to run our solutions on all of the major cloud platforms including AWS and Azure, and are not limited to GCP.)
Further, looking at the schema, there are a number of categorical and numerical variables:
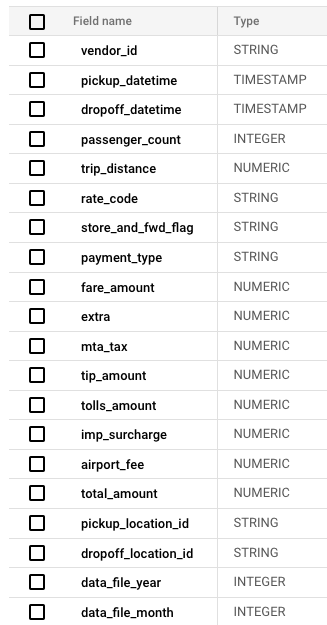
For our data science partners, they can begin to build models right from Jupyter notebooks on our platform. As a first step, they typically specify the numeric and categorical features:

Further, they specify the location in the Cloud DB of the table in question, and we then apply a set of seamless functions that we have built that specifically load the data, filter and clean it and prepare it for our distributed computing setting:

In this case, because the client was interested in forecasted, they specify a target column and our platform recognizes this as a regression problem.
We then split the data, train a highly specialized random forest model, calculate the RMSE. Once again, the data scientist just has to call our highly optimized and simple to use functions:

The progress of each stage is output to the notebook as well:

When the model training completes, the test-set RMSE is produced as well along with a plot of feature importances:

In just a few minutes, a company’s data science team can be up and running building very robust models against very large datasets with ease. We have helped a number of companies adopt these solutions. If this is of interest to you, please contact us and we would be more than happy to discuss your options and potential solutions: https://witenatech.com/contact-us/
